引言
在这个信息爆炸的时代,我们每天都在接触着大量的数据和资料。随着大数据和人工智能技术的发展,如何从海量的数据中提取有价值的信息成为了一个重要的课题。特别是对于像彩票这样的预测性活动,精准的资料和统计材料分析能力成为了取胜的关键。本文旨在针对2024年的“天天彩”活动,探索并解释一种多维统计材料设想——“多维版16.371”。我们将从多个维度对这一设想进行深入分析,以期为彩票爱好者提供一种全新的、科学的数据分析工具。
多维版16.371的基本概念
多维版16.371是一种基于统计学和概率论的多维分析模型,它将彩票号码的每一个属性视为一个维度,通过分析这些维度之间的关系,来预测彩票的中奖号码或趋势。这种模型在16个不同的维度上进行分析,每个维度代表一个特定的统计特征或者号码属性。通过综合这些维度上的信息,我们可以得到一个更加全面、准确的预测模型。
数据来源与处理
首先,我们需要收集天天彩的历史开奖数据,包括但不限于每期的开奖号码、销售额、售票时间等。这些数据的来源可以是官方发布的数据公报,或者是通过权限合法的数据抓取获得。数据处理的第一步是数据清洗,去除无效、重复或错误的数据记录,以便得到一个干净、准确且连续的历史数据集。
数据处理的第二步是特征提取,从历史数据中提取对预测有价值的特征,包括但不限于每个号码的频次、次数、间隔、最近一次出现的时间等。这个步骤是多维分析模型的基石,决定了模型的预测准确性和可靠性。
模型构建与参数调整
在确保数据处理无误后,我们开始构建多维版16.371模型。构建过程中,我们需要选择合适的统计工具和算法,比如回归分析、决策树、随机森林等。每种算法都有其特定的优势和适用场景,因此需要根据实际的数据特征和预测目标来选择最佳方案。
模型构建完成后,参数调整是非常重要的一个步骤。多维分析模型中包含许多不同的参数,这些参数需要通过调优来确定最佳值。可以使用交叉验证、网格搜索等方法寻找最优参数组合,并确保模型的泛化能力。
维度间的关联性分析
在得到初步的模型之后,我们将进一步分析不同维度之间的关联性。维度间的关联性对预测结果的准确性有着重要影响。通过计算不同维度之间的相关性或者协方差,我们可以识别哪些维度具有高相关性,哪些维度之间存在互相制约或者促进的关系。这些信息将帮助我们对模型进行微调,以获得更精确的预测结果。
验证与修正
模型构建完毕后,我们需要用历史数据对其进行验证,评估模型的准确性和稳定性。这一步骤包括计算模型的预测误差、胜率等关键指标。如果预测结果与实际开奖结果存在较大偏差,我们需要对模型进行修正,可能涉及到重新选择算法、调整参数、补充特征等。
修正后的模型需要进行多轮验证,直到预测结果达到理想的准确度为止。需要注意的是,过度优化的历史数据可能会导致模型在新数据上的泛化能力下降,所以我们需要在模型优化和过度拟合之间找到平衡。
预测结果的应用
对于预测的结果,我们可以将其转化为具体的购彩策略。例如,可以根据预测结果来确定投注号码、投注金额等。此外,还可以根据预测的中奖几率,对号码进行加权购买,以提高中奖的概率。这些策略需要结合个人的实际情况和风险偏好,灵活调整。
结论
多维版16.371模型作为一种创新的统计材料设想,为预测彩票中奖号码提供了一种新的视角和方法。通过结合历史数据、多维分析和机器学习技术,我们可以从多个角度预测彩票的走势,从而为购彩者提供更加科学的参考依据。当然,彩票本身具有相当大的随机性和不确定性,任何预测模型都无法保证100%的准确率,因此本文所提出的多维版16.371模型更像是一种辅助购彩的工具,它能够帮助购彩者在众多不确定性之中寻找相对的确定性。
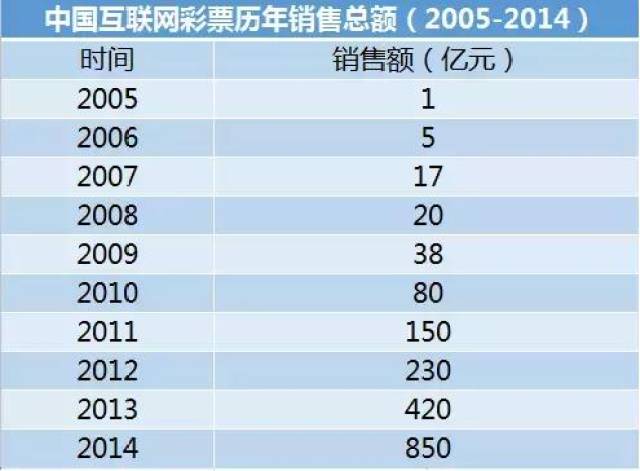
未来的研究可以进一步探索不同彩票特征和统计方法对预测效果的影响,以及如何在不断变化的彩票市场中调整和优化模型,使其更好地服务于彩票预测。